READ TABLE Finally Knows WHERE
{kind=link}
The canonical way to find the first internal-table row matching an arbitrary condition in ABAP has always been this:
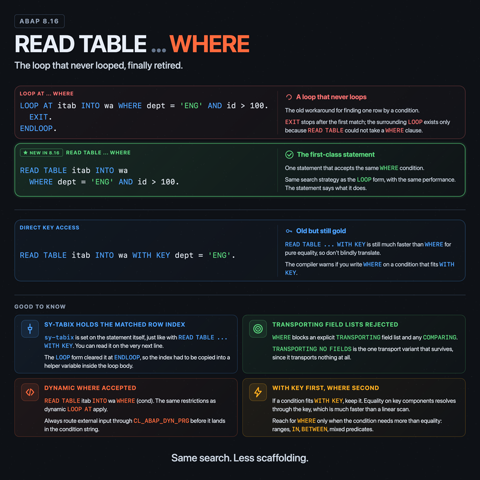
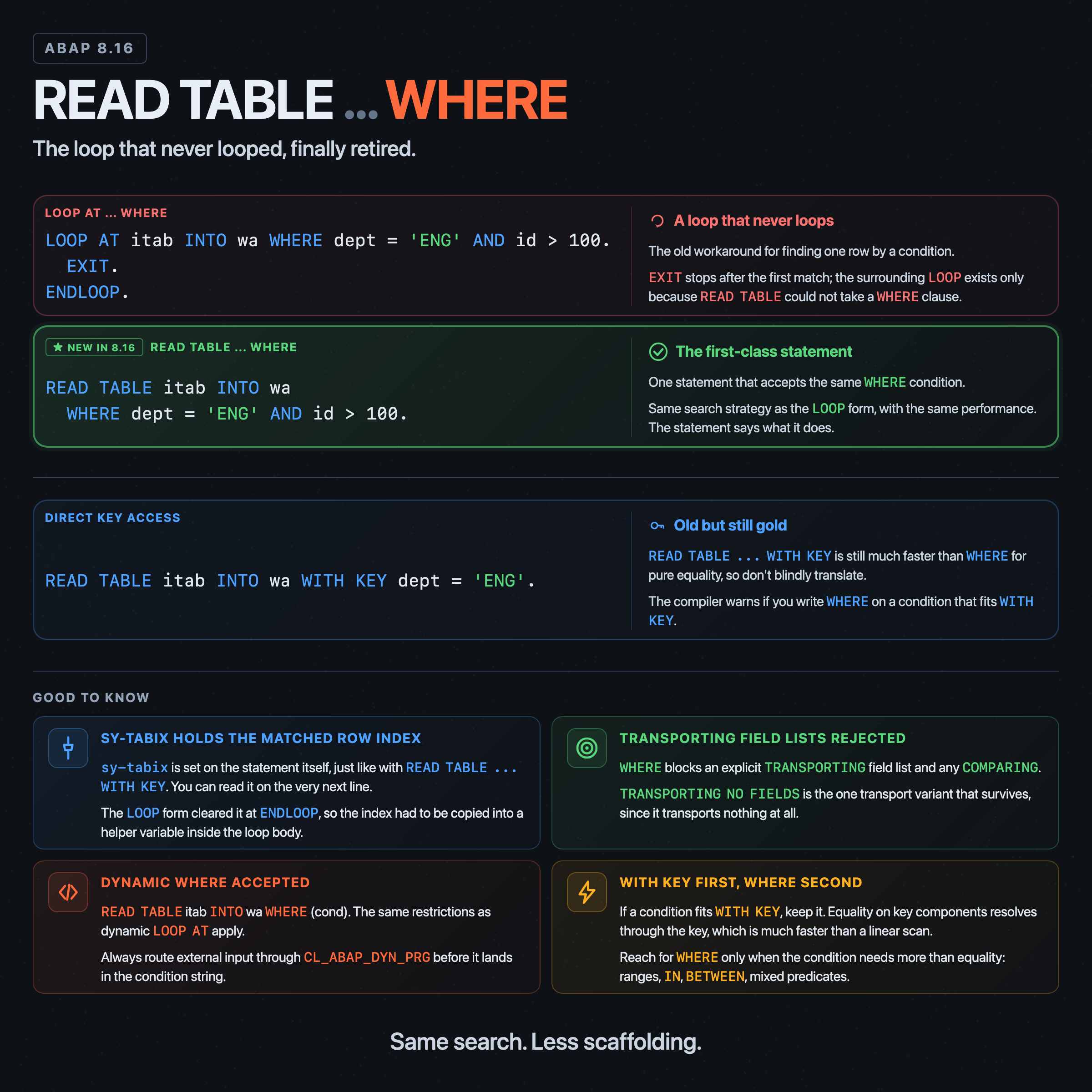
LOOP AT itab INTO wa WHERE dept = 'ENG' AND id > 100.
EXIT.
ENDLOOP.
A loop that never actually loops. The EXIT is doing the only work, and the surrounding LOOP ... ENDLOOP is just there because READ TABLE could not take a WHERE condition. You either accepted that, or you fell back to READ TABLE ... WITH KEY ... and gave up anything richer than component equality.
ABAP Release 8.16 fixes this. READ TABLE now accepts WHERE.
The new form
READ TABLE itab INTO wa WHERE dept = 'ENG' AND id > 100.
That is the entire change. One statement, same semantics: the table is searched for the first line whose values match the condition. sy-subrc is 0 on a hit, 4 on a miss. On a hit, sy-tabix is set to the line number in the used table index, or to 0 when the access goes through a hash key.
The SAP Keyword Documentation does not pretend this is anything more than what it is. Quoting the official page:1
The statement
READ TABLE itab ... [USING KEY ...] WHERE log_exp|(cond_syntax).works almost exactly in the same way asLOOP AT itab ... [USING KEY ...] WHERE log_exp|(cond_syntax). EXIT. ENDLOOP.
It is syntactic sugar. SAP says so directly. The release notes for 8.16 repeat the point: the syntax "offers an easier to use alternative to the following frequently used pattern but does not offer any performance gain."2
That is the right framing. Nothing about how the search runs has changed. What has changed is that the code now matches the intent.
The sy-tabix difference
There is exactly one behavioral asymmetry with the loop form, and it concerns sy-tabix.
In LOOP AT itab WHERE ... EXIT. ENDLOOP., sy-tabix is set inside the loop body. After ENDLOOP, it is restored to whatever value it held before the loop, so the row index from the iteration is gone. If you wanted it, you had to copy it into a helper variable inside the loop:
DATA idx TYPE sy-tabix.
LOOP AT itab INTO wa WHERE id > 100.
idx = sy-tabix.
EXIT.
ENDLOOP.
With READ TABLE ... WHERE, sy-tabix is set on the statement itself, the same way it has always behaved for READ TABLE ... WITH KEY:
READ TABLE itab INTO wa WHERE id > 100.
DATA(idx) = sy-tabix.
Small on its own, but it removes noise across a codebase that does this a lot.
What targets are allowed
Everything you would expect from READ TABLE:
READ TABLE itab INTO wa WHERE name = 'Charlie'.
READ TABLE itab ASSIGNING <fs> WHERE name = 'Charlie'.
READ TABLE itab REFERENCE INTO dref WHERE name = 'Charlie'.
READ TABLE itab TRANSPORTING NO FIELDS WHERE id > 2.
TRANSPORTING NO FIELDS is the only transport option permitted with WHERE. An explicit TRANSPORTING f1 f2 ... field list, or COMPARING, is rejected by the syntax.
Dynamic WHERE
The other variant follows the same convention as LOOP AT itab WHERE (cond_syntax):
DATA(cond) = `dept = 'ENG' AND id > 100`.
READ TABLE itab INTO wa WHERE (cond).
An invalid expression raises CX_SY_ITAB_DYN_LOOP when the condition is actually evaluated. The condition is not evaluated for an empty table, so a syntactically invalid cond against an empty table will not raise. An initial cond evaluates as true, so the first row of the table is returned. The same dynamic-WHERE restrictions apply: no string or bit expressions, no string functions, no time stamp functions other than utclong_current, no constructor expressions, no table expressions. If you have written dynamic LOOP AT ... WHERE, you already know the rules.
The usual warning applies to dynamically constructed conditions: anything coming from outside the program must be checked or escaped before it lands in a WHERE clause. CL_ABAP_DYN_PRG exists for this reason.
How it compares to WITH KEY
READ TABLE ... WITH KEY and READ TABLE ... WITH TABLE KEY are not going away, and they should not. WITH KEY is a free search key whose components you define inline; WITH TABLE KEY addresses an actual primary or secondary table key. Both are restricted to component equality, and that restriction is what lets the compiler resolve the access through a key directly whenever the specified components align with one. On sorted and hashed tables, or with a suitable secondary key, that means no scan.
READ TABLE ... WHERE does not get that optimization for free. On a standard table without a secondary key, it walks the table line by line. On a sorted or hashed table the compiler will try to transform the relevant part of the WHERE into a key access, but the prerequisites are real: the expression has to be transformable into a key lookup, and the transformable part has to produce the same result as that key lookup. When the condition does not fit and the access is through the primary key, the table is scanned. When the access is through a secondary key and the condition cannot be transformed, the compiler raises a syntax error or an exception instead of silently scanning, so USING KEY my_secondary WHERE ... is not a free fallback path.
The documentation is explicit about the consequence:1
For a WHERE condition that could also be expressed by
WITH KEY, the latter has a better performance. If such a WHERE condition is used, a syntax warning occurs that can be suppressed by the pragma##read_where_ok.
So the rule is:
- If your condition is pure equality on any set of components, use
WITH KEY(orWITH TABLE KEYwhen those components form an actual table key). The compiler will warn you if you writeWHEREin that case anyway. - If your condition is anything richer than equality (ranges,
IN,BETWEEN, negations, mixed predicates), useWHEREand stop building a single-iterationLOOParound it.
There is also a quieter, easy-to-miss distinction documented under the new statement: WHERE follows the comparison rules for incompatible data types, while WITH KEY converts the right-hand operand to the column type before comparing. They can produce different results when the operands have different types. If you are translating a WITH KEY access to WHERE, keep the operand types aligned; otherwise the same data can stop matching.
A small but real upgrade
This change is in the same category as RETURN expr. or LOOP AT ... STEP. None of these reshape how you architect ABAP. They flatten patterns that the language had been forcing you to spell out by hand.
LOOP AT ... WHERE. EXIT. ENDLOOP. was always a workaround. The new READ TABLE ... WHERE is what the workaround was working around. The performance characteristics do not change, the search strategy does not change, but the code stops lying about what it is doing.
READ TABLE ... WHERE requires ABAP Release 8.16. Older releases still need the loop pattern, or WITH KEY where it applies.
Sources
Footnotes
-
SAP Help, READ TABLE, where_cond ↩ ↩2
-
SAP Help, ABAP News for Release 8.16: Internal Tables ↩